Regular Addition of New Sample Enterprises to All Enterprises Tankan
February 22, 2002
Bank of Japan
Research and Statistics Department
From the March 2002 Tankan survey, 71 enterprises will be added to the sample of All Enterprises Tankan (Short-term Economic Survey of Enterprises in Japan).
In order to prevent a decline in the statistical accuracy due to a decrease in the number of sample enterprises caused by bankruptcies, mergers and so on, the following measures have been taken for All Enterprises Tankan. First, the statistical accuracy has been regularly examined (once a year) in terms of whether the distribution of the sample enterprises deviated from that of the population enterprises and whether the error ratios of the population estimates in sales remained within the target range (3 percent for the manufacturing industry and 5 percent for the non-manufacturing industry). Second, when the result of the examination revealed that the statistical accuracy had actually declined, new sample enterprises have been added using random sampling method. (See "The Methodology of the Sampling and Aggregation of All Enterprises Tankan" <Bank of Japan website> for details.)
This time, the statistical accuracy of the last Tankan survey (December 2001) has been examined, and 71 enterprises have been added to the sample (In choosing new samples, enterprises with less than 20 million yen in capital were excluded beforehand, since they are going to be omitted from the sample enterprises in the next renewal of Tankan scheduled in FY2003). As a result, the total number of the sample enterprises for the March 2002 Tankan will be 8,651. The details are as follows:
(1) Distribution of the sample
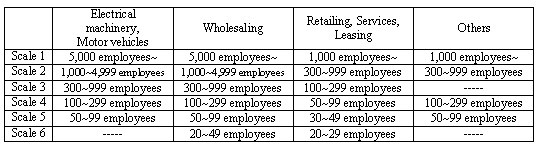
In All Enterprises Tankan, the sample is classified into 118 divisions by industry and scale (based on the number of regular employees). Each division was examined in terms of whether the distribution of the sample enterprises (in the number of regular employees) appropriately reflected that of the population enterprises.
The result of the examination revealed that the distribution of the sample had deviated from that of the population in 4 divisions1.
In addition, there were divisions of which the sample distribution indicated a high likelihood of deviating from the distribution of the population in the future due to a possible decline in the number of sample enterprises.
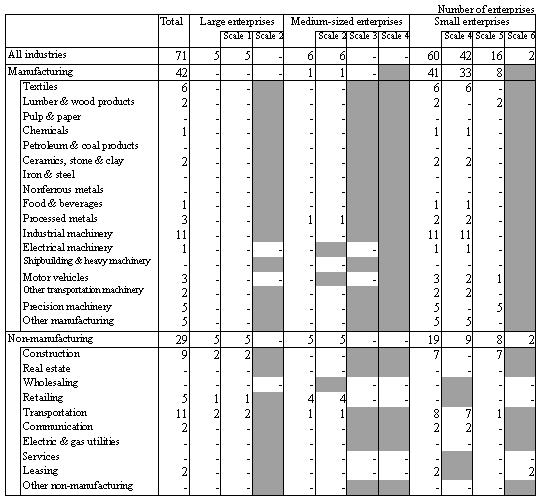
With a view to maintain the statistical accuracy, sample enterprises were added to these divisions (71 enterprises; see the appendix for details).
(2) Error ratios of the population estimates
For all of the main six divisions by industry and scale (Manufacturing/Non-manufacturing and Large/Medium-sized/Small, see below), the error ratios of the population estimates (in sales2) after the addition of 71 samples mentioned above, remained within the target range .
Error ratios (in sales) after the addition of 71 sample enterprises

- The "test of the goodness of fit" using chi-square distribution is used in the regular examination. This method tests the null hypothesis, H0"The distribution of the sample and that of the population have the same shape." When the hypothesis is statistically rejected, it is judged that there is a difference between the distribution of the sample enterprises and that of the population enterprises.
- Population estimates based on sample surveys, like those in All Enterprises Tankan, inevitably entail certain estimation errors. Users are advised to take this into consideration when using the data. All Enterprises Tankan is designed to keep the actual figures basically within the range of 3 to 5 percent around the population estimate.
For further information, please contact:
Business Survey Group, Economic Statistics Division,
Research and Statistics Department
Bank of Japan
Address: 2-1-1, Nihonbashi-Hongokucho, Chuo-ku, Tokyo 103-8660 Japan
Email: post.rsd5@boj.or.jp
(Appendix)
Number of Sample Enterprises Added by Industry and Scale
- Note:Large, medium-sized, and small enterprises are divided into subgroups by scale upon calculating the population estimates. Subgroups do not exist for the shadowed cells in the above table. The definition of the subgroups by scale is shown below: